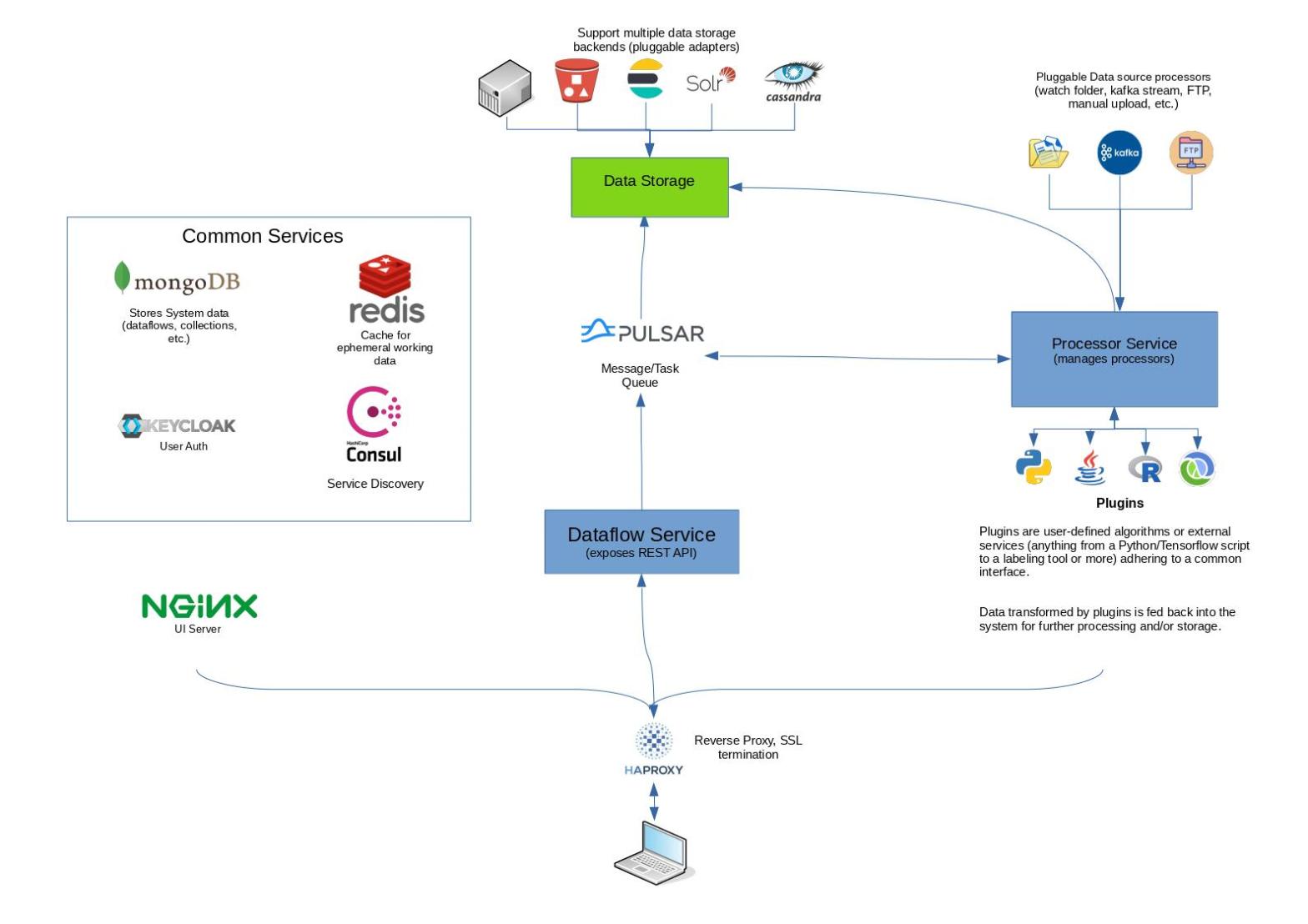
For the past couple of months I’ve been working on a data management tool I’m calling OpenDMP (see my earlier post). As I’ve started adding more features, I’ve run into a scalability issue a bit sooner than I had expected and so I decided to tackle what is hopefully the biggest remaining piece of theContinue reading “A Plugin architecture with Spring, Consul, and Camel”
Category Archives: Development
My Lock-down Project: A Data Management Thing

Visit the Github repo for this project I tend to write code when I get bored. I figure it’s been two years since my last blog post so maybe I ought to actually finish one of the several half-finished drafts I have sitting around and publish it. Or maybe I’ll just write a new blogContinue reading “My Lock-down Project: A Data Management Thing”
Golang – The Okayest Programming Language

Note: This is a repost (and expansion) of my quora answer here. Someone on Quora recently posted a question asking for developers to discuss their negative experiences with Golang. That got me thinking about my past (and current) experiences with the language, and I ended up replying with a list of pros and cons: It’sContinue reading “Golang – The Okayest Programming Language”
Building a SaaS product with Clojure
The Idea Like many software developers, I spend a lot of my spare time on side projects. Some side projects are purely for my own edification: learning a new language (such as my current favorite, Clojure), or exploring a new technology or problem domain. However, a great many project ideas that tend to pop intoContinue reading “Building a SaaS product with Clojure”
On Boards and Cards

Unless you’ve been living under a rock, you’ve doubtless noticed the current trend in project management tools involving “boards full of cards.” Trello is probably the most well known (and cheapest, being free, which might have something to do with its popularity) of this archetype. Other, more elaborate (and expensive) enterprise tools have implemented “agile”Continue reading “On Boards and Cards”
Implementing Search-as-you-type with Mithril.js
I’ve been working on a new project, the front-end of which I’m coding up in ES6 with Mithril.js (using 1.0.x now after spending the better part of a day migrating from 0.2.x). I wanted to implement “search as you type” functionality, since I’m using Elasticsearch on the back-end for its full-text search capability. Took meContinue reading “Implementing Search-as-you-type with Mithril.js”
Thoughts On Java 8 Functional Programming (and also Clojure)
After working with Java 8 for the better part of a year, I have to say I find its new “Functional” features both useful and aggravating at the same time. If you’ve used true functional programming languages (or you use them on your own personal projects while being forced to use Java at work), you’llContinue reading “Thoughts On Java 8 Functional Programming (and also Clojure)”
C and Go – Dealing with void* parameters in cgo
Wrapping C libraries with cgo is usually a pretty straightforward process. However, one problematic situation I’ve come across recently is dealing with C functions which take a void* type as a parameter. In C, a void* is a pointer to an arbitrary data type. I’ve been using one C library which allows you to storeContinue reading “C and Go – Dealing with void* parameters in cgo”
Making an extensible wiki system with Go
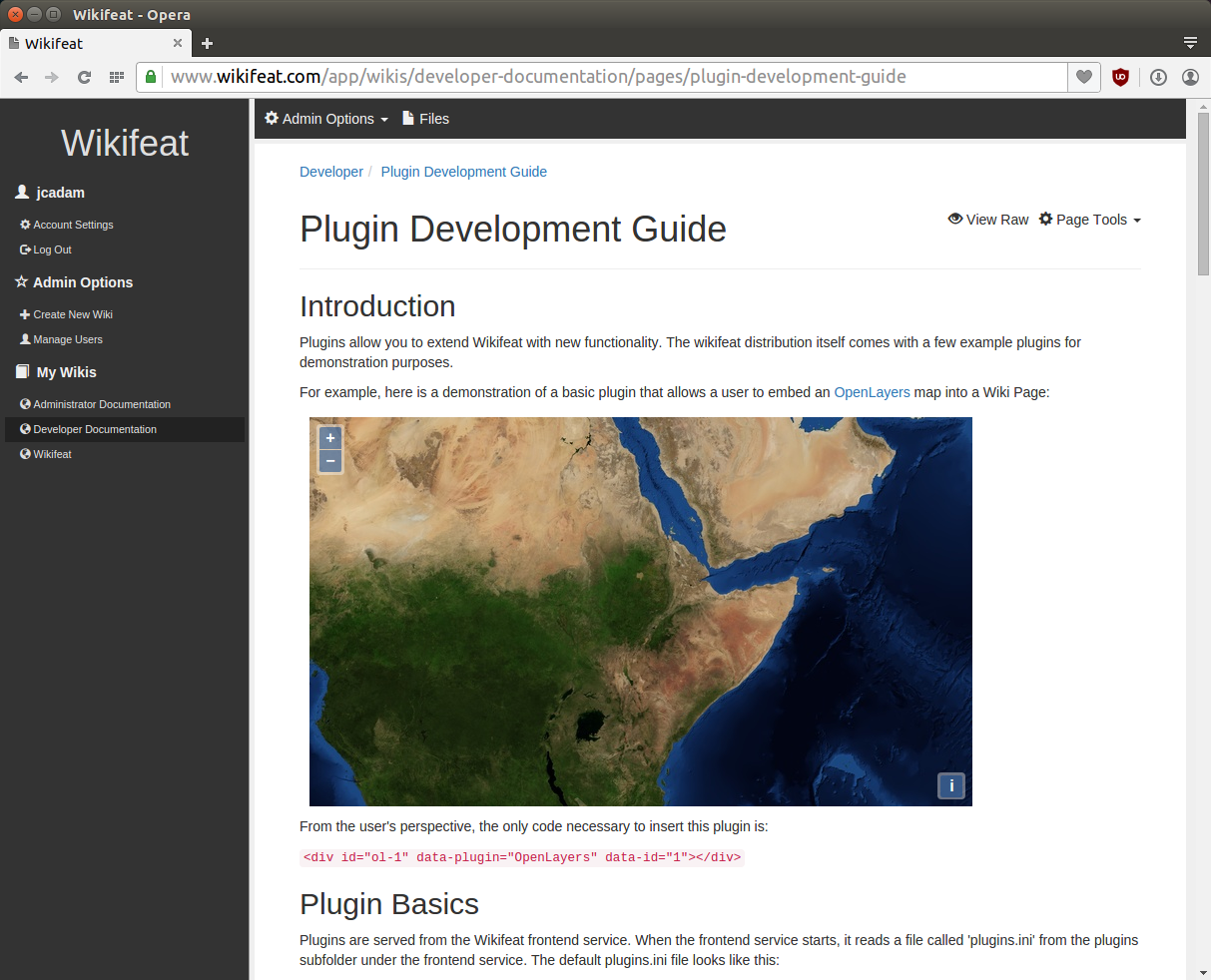
My little side project for roughly the last year has been a wiki system intended for enterprise use. This certainly isn’t a new idea — off the top of my head, I can think of several of these “enterprise” wiki systems, with Confluence and Liferay being the most obvious (and widely used) examples. The problemContinue reading “Making an extensible wiki system with Go”
Creating RPMs from python packages
While I can use pip to install additional python packages on my development box, sometimes I need to deploy an application into an environment where this isn’t possible. The best solution if the target box is an RPM-based linux distro is to install any necessary python dependencies as RPMs. However, not all python packages areContinue reading “Creating RPMs from python packages”
