
Visit the Github repo for this project
I tend to write code when I get bored.
I figure it’s been two years since my last blog post so maybe I ought to actually finish one of the several half-finished drafts I have sitting around and publish it. Or maybe I’ll just write a new blog post talking about the little personal project I’ve been working on for the past few months.
Yep, that sounds more fun, I’ll do that.
So, like most of us I’ve had some extra time on my hands since this COVID situation started, and I happened to get an idea for a new project. I’m terrible at naming things (see: Contabulo), so I just gave up on trying to be clever and went with a boring, generic, somewhat descriptive name for this project: Open Data Management Platform (OpenDMP). Open, because it’s open source, and “Data Management Platform” because it’s a platform that… manages data.
Motivation
Well, the motivation for this little project was to create a generic data management system that can serve as a common starting point for new data projects and help prevent the proliferation of bespoke solutions that are being implemented for every single organization, project and/or program. In short: To help engineers stop reinventing the wheel for every project involving data processing and management. I think there’s a lot of common functionality at least for small to medium-scale needs (obviously, there’s no getting around the need for custom solutions for organizations dealing with highly specialized data/use cases or truly massive volumes of data. But such organizations probably have the time, inclination, and in-house talent necessary to build whatever they need).
I’d like to think I’m targeting users that have been manually processing data with scripts on their own workstations and are in need of something a little bit more automated and robust.
How Does it Work?
The idea is to allow users to design simple data flows that ingest data, perform transformations and/or run data through different scripts and external tools, and export the data elsewhere (could be the file system, object storage, a database, etc).

A user constructs a flow made out of processors organized into “phases.” Processors can be of various types, for example: Ingest, for bringing data into the system, Script, for executing basic transformations on data, Collect, for collecting results and exporting them to external data stores, and more. Phases are meant to help the user layout the dependencies between processors (i.e., a flow should run in phase order), although it should be noted the system doesn’t necessarily obey this order if a processor lacks a hard dependency on a previous phase.
Here’s a basic example of a Script Processor:

This is a super-simple example that just takes in a string and converts it to upper case. As you can see, this processor allows you to write an arbitrary script in Python that modifies your data and passes it along to the next processor in the flow (As an aside, the Script Processor supports Clojure as well – I couldn’t resist adding support for my favorite language). The flow interface is also nice enough to let you know when something goes wrong:

When data is collected, it is exported to an external data source, and an entry is made into a “Collection” of the user’s choice:

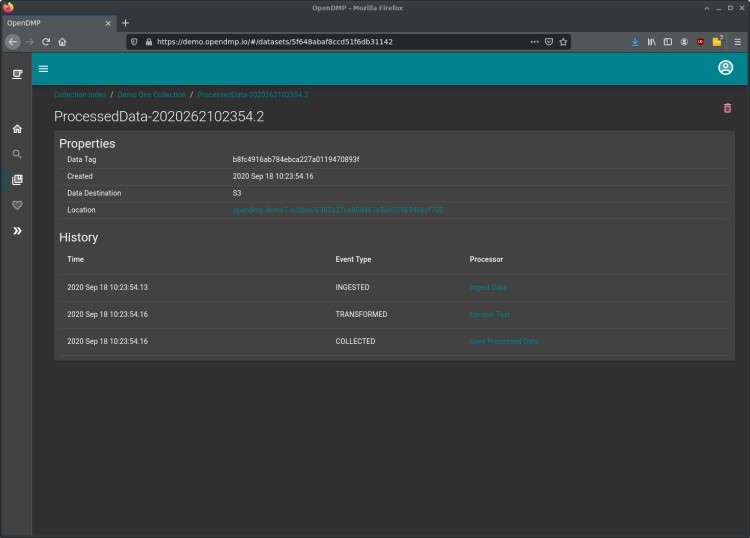
Currently only a few rudimentary types of processors are available, but I definitely plan to expand this. It’s a design goal that OpenDMP be expandable with Plugin processors, for example.
Technology
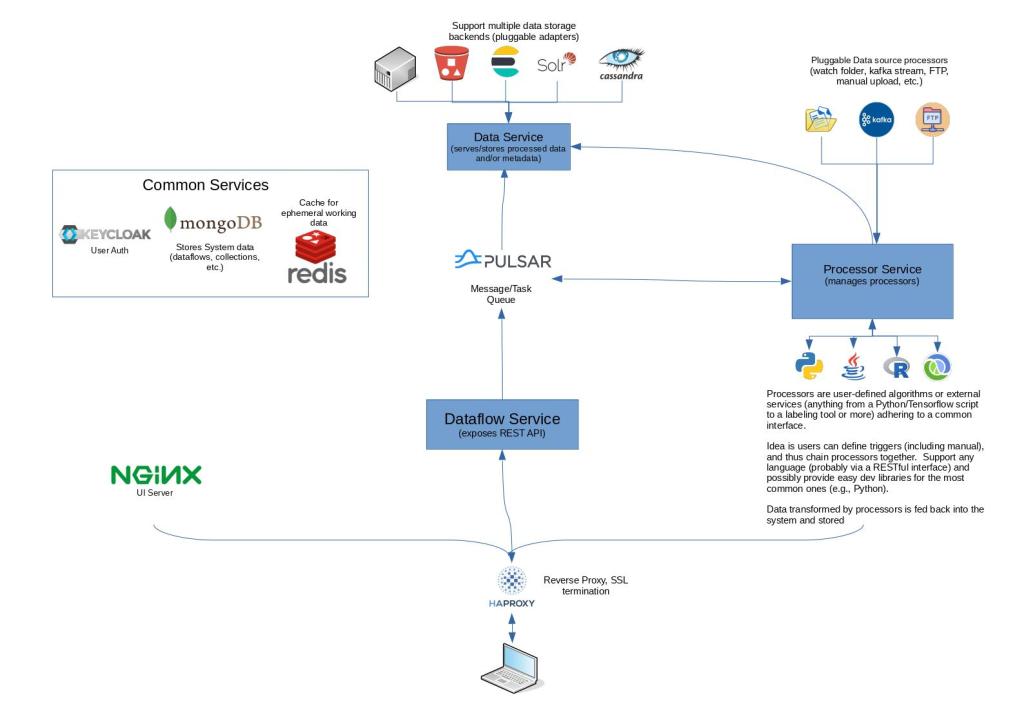
If I haven’t lost you yet, read on as I delve into the architecture and technical details of OpenDMP:
First, OpenDMP is a system made up various services running in a containerized environment. It does not make any assumptions about your container orchestration solution (there are sample docker-compose files in the repo), since that choice should be dictated by your workload, infrastructure, and ops expertise. Also, beyond the core services required to run a basic system, users will probably want to run additional services (databases, external tools, etc.) that interact with OpenDMP within their environment.
Core Services
The frontend consists of a re-frame application written in Clojurescript. This was my first project using re-frame and Clojurescript and I found it to be a huge win over javascript. State management in particular was much less of a problem than I’d experienced on previous projects. The astute observer will probably notice the use of Material-UI as well. I found integrating Material-UI components with re-frame to be completely painless.
The backend services are written in Kotlin using Spring Boot. The Dataflow Service exposes an API for the frontend and owns the MongoDB database that stores dataflow, processor, and collection information. The Processor Service (also Kotlin + Spring Boot) is where the data flows are actually “run.” It relies heavily on Apache Camel to control the flow of data through the system. It also uses a Redis cache to keep track of things as it executes dataflows. If you’re wondering how the scripting support works, Clojure can be evaluated by the Clojure interpreter right on the JVM, whilst Python support is achieved using Jep, which embeds CPython in the JVM via JNI (I thought this a better solution than Jython).
Communication between the various backend services utilizes Apache Pulsar, which is starting to get a lot of attention as a Kafka alternative. Before I came across Pulsar in my research, I was torn between Kafka and using a traditional message broker such as RabbitMQ. Pulsar makes an attempt at combining the functionality of both, and at least so far appears to do a fairly decent job of it.
OpenDMP uses OpenID for auth and Keycloak, a widely used SSO and Identity Management solution, is used to handle Identity and Access Management. In fact, user management is completely absent from the rest of the OpenDMP system as well as the frontend. From a development perspective, this simplified things tremendously. The use of an industry-standard auth mechanism (OpenID) should also help in situations where OpenDMP needs to be integrated into an existing enterprise architecture.
Everything sits behind HAProxy that does reverse proxying and ssl termination.
How a Dataflow Runs
So, what happens when you build a dataflow in the UI and click the “enable” button? Well, after the request is sent to the Dataflow API, the following sequence is executed:
- The Dataflow Service loads the Dataflow and creates a “Run Plan.” It does this by analyzing the dataflow and mapping out the dependencies between processors to determine the order in which different processors need to be executed, and which can be run in parallel. Note: “Phases” are ignored here in favor of finding the most efficient way to execute the dataflow – phases are a device of the UI/UX to help users layout their flows.
- The Run Plan is sent to the Processor Service. It contains everything the Processor Service needs to run the dataflow.
- The Processor Service goes through the Run Plan and generates Camel routes and begins executing them immediately.
- Errors and/or Collection results are sent back to the Dataflow Service via Pulsar.
It sounds simpler than it is, I promise 🙂
Future Plans
Quite a bit of the functionality I’ve got planned hasn’t been done yet, of course, and OpenDMP is definitely not production-ready at the time of this writing. There’s still critical features to be added and much proofing to do on various workloads. Big features still to be added include:
- Aggregation Processors – bringing divergent flow paths together again.
- Plugin processors – I’d like to see common Data Science/ML tools wrapped in OpenDMP API-aware services for clean integration in dataflows.
- UI improvements – In particular, better searching, sorting, etc. of Data sets
- Notification support – Send notifications to people when things go wrong (email, et al).
- Better scaling – While multiple instances of the processor services can be run to better support running many dataflows, within a dataflow it would be helpful to create worker nodes for the Processor service to distribute individual processor tasks using Camel and Pulsar.
- And of course, more ingest and export data stores need to be supported.
Final Thoughts
This has been a challenging and fun project so far to build, I hope others will eventually find it useful. Also, it’s open source, so contributions are definitely welcome!

This looks really good. You really focus on it as a minimum viable product and then scale it up as you go, I think it will do phenomenally well with that model. All the best for the future, I hope this works wonders for you.
LikeLike