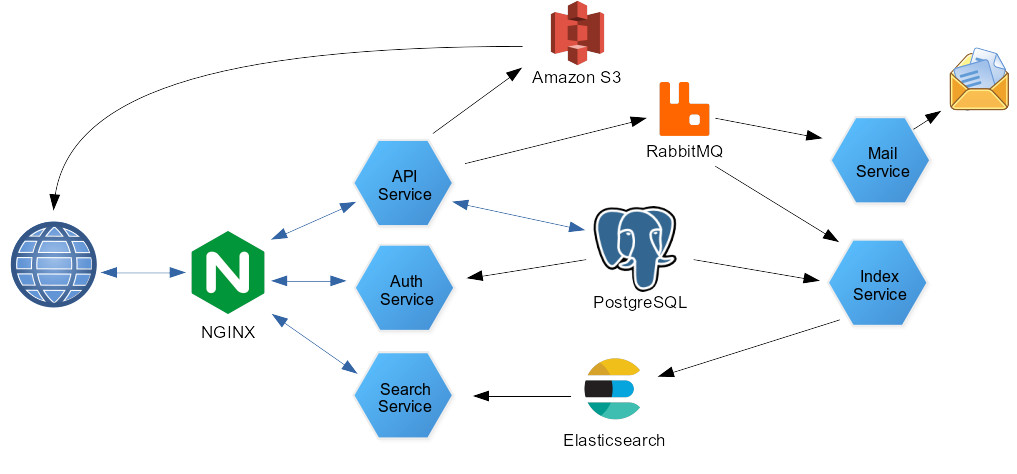
For the past couple of months I’ve been working on a data management tool I’m calling OpenDMP (see my earlier post). As I’ve started adding more features, I’ve run into a scalability issue a bit sooner than I had expected and so I decided to tackle what is hopefully the biggest remaining piece of the project’s system architecture.
The Need for Plugins
From the architecture diagram at the top of this post, you can probably tell that the “Processor Service” is where most of the work for OpenDMP gets done. Dataflows are designed by users in a web app and then handed off to the Processor Service, which sets up Apache Camel routes to ingest, transform, and then store the results. I wanted to allow users to run arbitrary scripts, programs, and/or tools on their data as it traverses their flow, so I created different types of processors users could add to their flows to enable this.
First, the Script Processor, which allows users to enter their own Python or Clojure scripts to transform their data which is then executed within the Processor Service.

Second, the External Processor, which runs an arbitrary command in an OS shell.

The problem? All of the OpenDMP services are running in containers, which means any external tools you want to run in your dataflow would have to be included in the Processor Container (in theory, a user would extend the opendmp-processor image and add whatever dependencies they need). This obviously won’t scale, as you would eventually end up with an enormously bloated processor service image if you needed to add more than a few dependencies. The Script processor, for example, already required me to add python support (along with a few key libraries, such as numpy) to the base image, which increased the image size considerably.
I realized when I started experimenting with other tools such as imagemagick and ffmpeg with the external processor, that solution just wasn’t going to work. So I needed to come up with something different. I’d had the idea for plugins early on, so I decided to tackle that now rather than continuing to put it off. I figured I could also use plugins to do something I’ve been wanting to do with the Script processor – get all the python stuff out of the base image 🙂
The Plugin Processor
So, enter a new processor type: the Plugin Processor.

The idea is that plugins run in their own containers, and are meant to do one specific thing. In the example above, the data would be a sent to a container with FFMPEG installed, which would run the user specified ffmpeg command line on the data and return the result to the flow.
Simple idea, but this introduces a new bit of complexity into the system. I no longer have a fixed collection of services running. I.e, OpenDMP has no way of knowing what plugins are going to be running on any arbitrary installation (not to mention the possibility of multiple instances of plugins). So, the first thing I knew I needed was a Service Discovery solution. For this, I chose Hashicorp Consul. It’s supported by both Apache Camel and Spring Boot, so I figured that would make integration easier.
Consul itself was simple enough to get running. The available images on docker hub work well and spinning up a small cluster was easy.

Apache Camel provides support for calling external services as part of a Camel route via the ServiceCall EIP. Combined with Spring Boot Cloud, Camel will automatically query Consul for an available instance and call the requested service, feeding the result back into the Camel route. Of course, error handling becomes important here – we’re relying on external services which may or may not be running, and user input and/or data which may or may not result in said service throwing an error. Fortunately, Camel provides the ability to specify an error handler on either a global, per route, or per processor basis, so I made use of the DeadLetter error handler to make sure I could report errors back to the Dataflow service so that they can be brought to the user’s attention.
Because I feel like I should include a code example somewhere in this post, Here’s how I’m calling external services in the processor service. Note I’m also using Camel’s Circuit Breaker EIP, because I already ran into a situation where an error resulted in Camel infinitely retrying to send the same bad request to a plugin 🙂
/**
* Make a service call!
*/
private fun serviceCall(route: RouteDefinition, proc: ProcessorRunModel) {
val service = proc.properties?.get("serviceName").toString()
val params = getQueryParams(proc)
route
.log("Making call to $service")
.circuitBreaker().inheritErrorHandler(true)
.serviceCall()
.serviceCallConfiguration("basicServiceCall")
.name(service)
.uri("http://$service/process?${getQueryParams(proc)}")
.end()
.endCircuitBreaker()
.log("completed call to $service")
.removeHeaders("CamelServiceCall*")
}
Note: I’m a little annoyed that the WordPress code block doesn’t support Kotlin syntax highlighting
Customizable Configuration

Besides specifying what plugin to run, it’s probable that users are going to need to specify some parameters for most plugins. In the case of our simplistic FFMPEG plugin, for example, the command line switches and options to provide to FFMPEG. So, how is the OpenDMP front-end supposed to know what parameters a random plugin is going to need?
To address this issue, I decided a plugin needed to expose two endpoints: “/process”, for processing data as part of a flow, and “/config”, to provide configuration information to OpenDMP.
Here’s an example config response from the ffmpeg plugin:
{
"opendmp-ffmpeg-plugin": {
"serviceName": "opendmp-ffmpeg-plugin",
"displayName": "FFMPEG Processor",
"type": "EXTERNAL",
"fields": {
"command": {
"type": "STRING",
"required": true,
"helperText": "The command line to pass to FFMPEG"
},
"timeout": {
"type": "NUMBER",
"required": false,
"helperText": "The amount of time (in seconds) to wait for FFMPEG to complete"
}
}
}
}
The Dataflow Service is given a list of enabled plugin names as an environment variable. It then queries all of the enabled plugins (retrieving instance information from consul, of course) for their config information. The UI can then retrieve this config information for a particular plugin and use it to build a form for the user to populate.
Extensibility Enabled
So, using plugins, we can add pretty much any capability we’d like to OpenDMP. Since the plugin services communicate over HTTP, a plugin could be implemented in any language. Right now, I’m whipping up a little SDK in Kotlin for JVM usage, but creating a simple SDK for, say, Python later should be a simple task. I also plan to use the plugin functionality “under the hood” for other processors (particularly, scripts) in order to get some dependencies out of the main Processor Service container, and of course, decrease the CPU load on that service.
So, this opens up a whole range of possibilities – A tensorflow plugin running in a CUDA-aware container is one possible example.
Thanks for reading, if you’re interested in digging through some code, check out the OpenDMP code repository here.