
Note: This is a repost (and expansion) of my quora answer here. Someone on Quora recently posted a question asking for developers to discuss their negative experiences with Golang. That got me thinking about my past (and current) experiences with the language, and I ended up replying with a list of pros and cons: It’sContinue reading “Golang – The Okayest Programming Language”
Tag Archives: Go
C and Go – Dealing with void* parameters in cgo
Wrapping C libraries with cgo is usually a pretty straightforward process. However, one problematic situation I’ve come across recently is dealing with C functions which take a void* type as a parameter. In C, a void* is a pointer to an arbitrary data type. I’ve been using one C library which allows you to storeContinue reading “C and Go – Dealing with void* parameters in cgo”
Making an extensible wiki system with Go
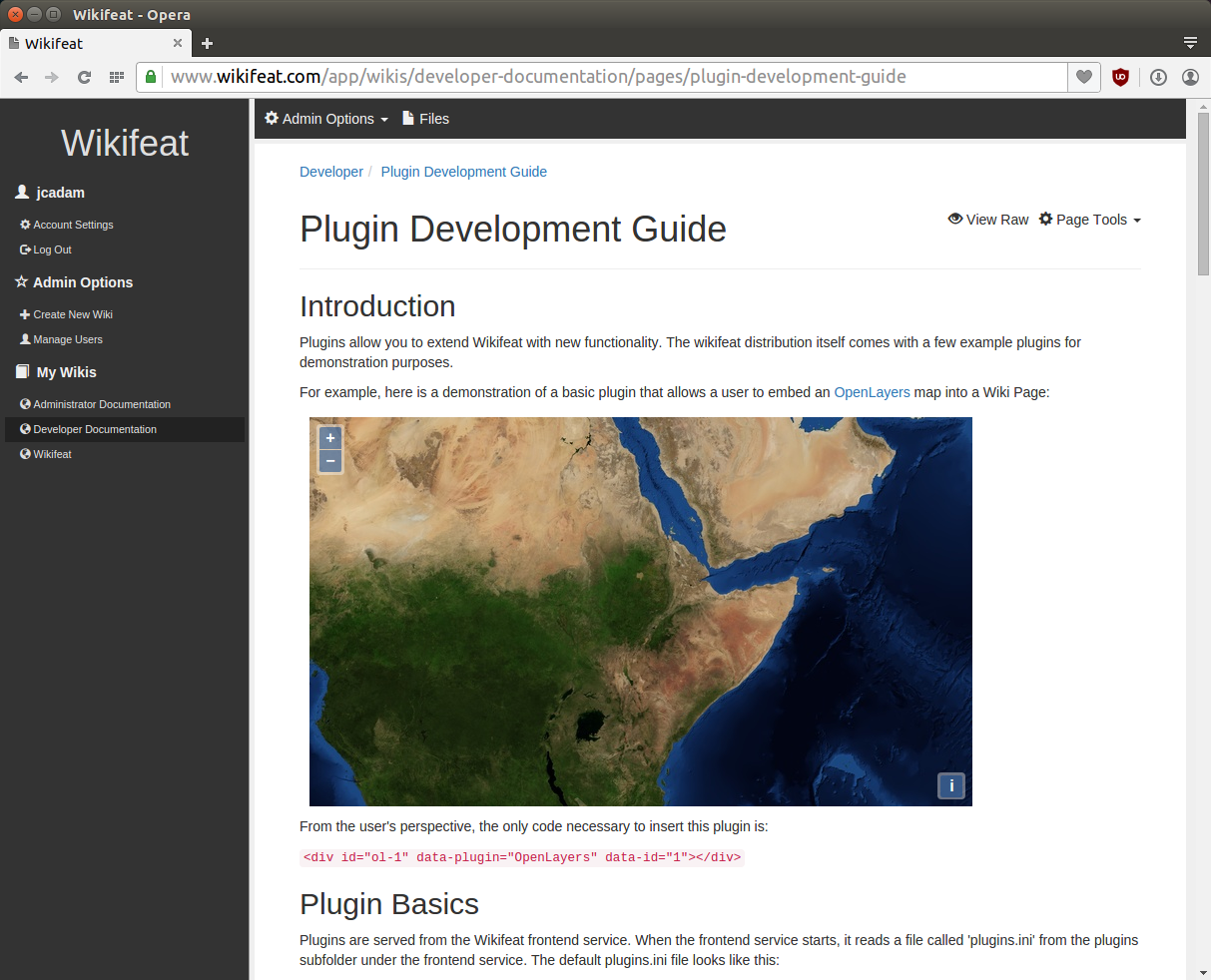
My little side project for roughly the last year has been a wiki system intended for enterprise use. This certainly isn’t a new idea — off the top of my head, I can think of several of these “enterprise” wiki systems, with Confluence and Liferay being the most obvious (and widely used) examples. The problemContinue reading “Making an extensible wiki system with Go”
Using C libraries with Go
On my current project, which involves wiki-esque collaborative editing of documents, I decided I wanted to use markdown. And since I wanted to use markdown (or rather one of the many almost-sort-of-compatible implementations of it), I decided that I might as well use CommonMark, which is attempting to introduce some sanity (standardization). I’m using Go,Continue reading “Using C libraries with Go”
Two weeks with Go
It’s been awhile since my last post, as I’m sure my legions of loyal readers have surely noticed….. surely. Anyway, since my last post I’ve moved my family from Northern Virginia to the Florida coast to take a new job (I’ve discovered that the DC area does not agree with me), so I’ve been aContinue reading “Two weeks with Go”
